
- Kscope16 (obviously). There I attended sessions of Brendan Tierney, Mark Rittman, and other bright folks which greatly stimulated my curiosity and desire to try new things with tools like Oracle Advanced Analytics, Oracle Data Miner, and Oracle R Enterprise.
- I talked to a few customers and data scientists, and we were trying to gather additional use cases of integrating predictive analytics tools with Essbase. Also I tried to survey those customers in terms of which tool they use for different functional areas. For example workforce predictive analytics, or what some of them call HR analytics, automating and bringing planning/budgeting/forecasting to the next level in term of accuracy.
As a result I decided to build another POC with the focus on Oracle Advanced Analytics and Data Miner. The business use case would be the same as in “Essbase Meets R”: automating P&L forecast with tools for predictive analytics. This time I will rely as much as possible on the built-in data miner and ORE (a.k.a. Oracle R Enterprise) functionality, and will compare two processes. Among other things I will compare accuracy, performance, scalability and ease of use of two processes. We’ll see how association models or clustering models of Oracle data miner can complement custom built process that integrates R with Essbase.
Another use case I would really like to cover is utilizing different statistical models for workforce planning. Specifically, with classification models you can predict certain decisions an employee is going to make.
If you can tailor a compensation and benefits package in a way that will minimize the probability of a specific employee leaving the company, you will achieve a few goals at the same time: minimize the cost related to hiring a new employee, have more accurate workforce planning, and probably will have a happy employee (or at least someone who will not want to leave).
The difficulty with that kind of POC is that it would require a data set with real compensations, demographics and other HR data to test the predictions. Which is obviously very sensitive, requires approvals, etc. So, if you are interested in partnership and can get approvals for data access - please feel free to reach out.
Since the amount of material I am planning to cover is definitely not for a single post, I decided to break it into several:
- Data Miner And ORE Introduction And Setup: my experience with installing and configuring ORE. I will refer to Brendan’s book (“Predictive Analytics Using Oracle Data Miner”) for step by step instructions, in my post I’ll just mention some results. Also, this is not an instruction of what you need to do in production environment, but simply a description of my experience, issues I encountered and how I solved them. It may or may not be relevant in other environments or make sense for a seasoned DBA.
- Descriptive Statistics With Data Miner
- Defining Sample Dimensionality With Data Miner Clustering
- Using Associations And Clustering Results In Regressions in Data miner
- Dynamic Models Creation With PL/SQL
- Integrating Oracle Data Miner with Essbase
- Comparison of custom Essbase-R integration with ODM-ORE-Essbase integration.
Data Miner And ORE Setup
As I mentioned, at Kscope16 I attended a session of Brendan Tierney, then bought his book “Predictive Analytics Using Oracle Data Miner”, and decided to see how it can complement/improve/replace a custom built process that integrates Essbase with R.
Also, instead of using stand-alone R we are going to use ORE (Oracle R Enterprise) and some native Oracle data mining algorithms.
Among the advantages of using ORE are:
- Data stays in Oracle. No need to move it to R server. In the example I was showing earlier (Essbase Meets R) I was using ODBC adapter for R. You don’t necessarily have to do extract and transform data outside of Oracle. You can clean the data in the query or PL\SQL procedure, and supply a final data set to R. But you are still moving the data over the network (if your R framework is installed on a separate server - which is probably the case). And you do need to load the sample into R’s memory.
- Native Oracle security. Again, if you had to extract the data into another target system, you would have to deal with security. But with ODBC connection you can use predefined Oracle accounts.
In order to use Data Miner you need to create ODM schema and DM repository. That’s the place where your workflows, nodes, results and other DM objects are stored.
My first observations are about installing Oracle Advanced Analytics Option and making it work. I have to say that i am not a DBA, but simply worked as a developer with Oracle for quite some time, and i did install different flavors of Oracle database on linux and Windows machines. The VM environment i wanted to use for Oracle data mining has Oracle Database 12c Enterprise Edition Release 12.1.0.1.0 - 64bit. I didn’t want to have a clean database install since all my data marts and repositories from prior R integration were already in this database. Here are a few traps I fell into (again - if i worked with experienced DBA it would save me quite some time).
- Oracle Data Mining repository can be created only in pluggable database. I tried to update the SQL scripts with “container” users (which was a bad idea regardless), but eventually got specific error telling that repository can only be created in a pluggable database.
- I did not have Oracle Database Examples installed. This would prevent me using text mining algorithms.
- Once the data mining repository is created we can create a simple workflow (say a Data Source and Explore Data nodes). It would look like this:
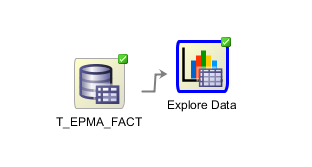
You can notice little green checkboxes in the right top corner of each node. That meant the workflow was already run. It took me awhile to actually make it run, apparently since DB scheduler was turned off. If you run the following statement:
select value from v$parameter where name='job_queue_processes';
|
You may find that the value is 0. And as Oracle database reference mentions “If the value of JOB_QUEUE_PROCESSES is set to 0, then DBMS_JOB jobs and Oracle Scheduler jobs will not run on the instance.” To turn it ON, run the following command to update the value:
ALTER SYSTEM SET JOB_QUEUE_PROCESSES = 100;
|
Once we ran the workflow we can right click Explore Data node and select “View Data”. There we can see some nice histograms by dimension. But we’ll see in the next post how those can be used.
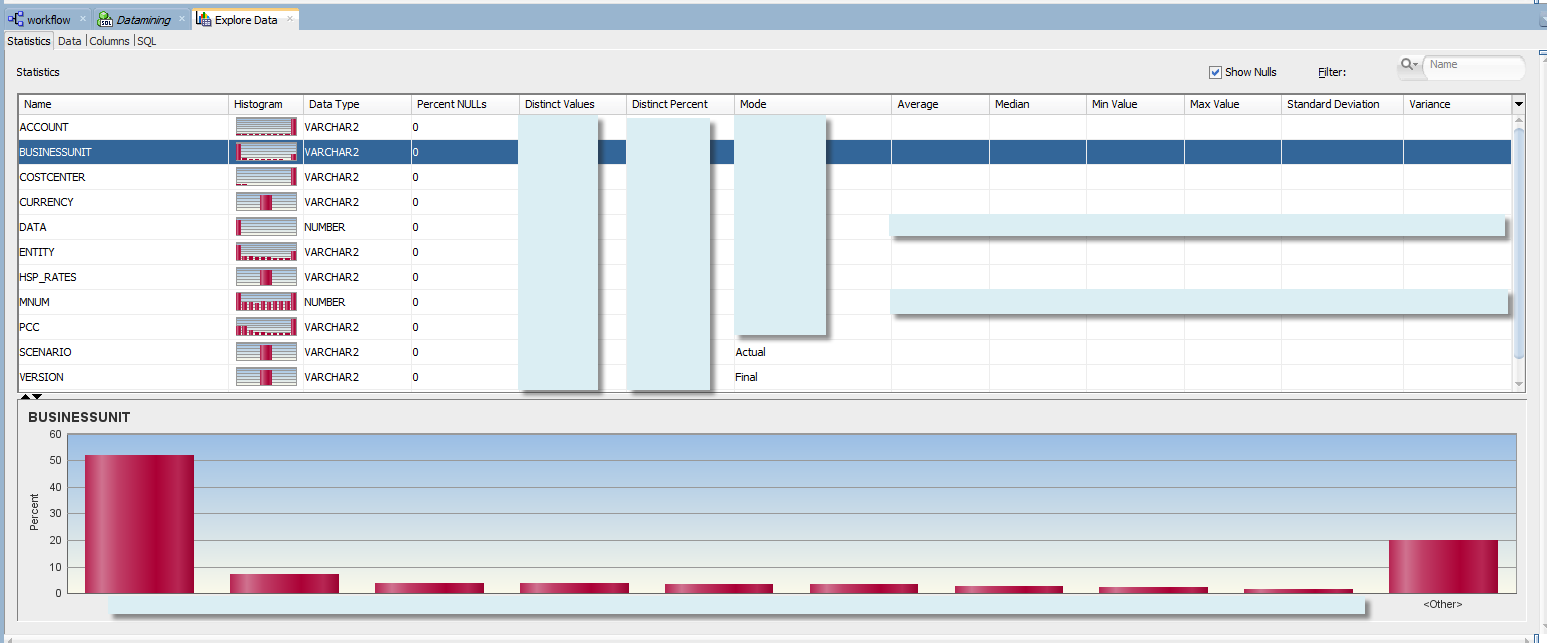
Data Miner SQL Query
An interesting feature of SQL Query is that you can call R scripts if you have Oracle R Enterprise installed on the server. Technically, it’s not the feature of ODM, and you can call R scripts from SQL in general once the prerequisites are met. This document describes steps require to install ORE. Specifically on my VM i had to do the following:Install Oracle R distribution (see documentation here)
Update public-yum-xxx.repo to include xxx_addons
yum install R-Rversion
Download R enterprise server
Run ORE install (./server.sh -i)
At this point a new tab appeared in SQL Query node, and you can write your first embedded R script in ORE:
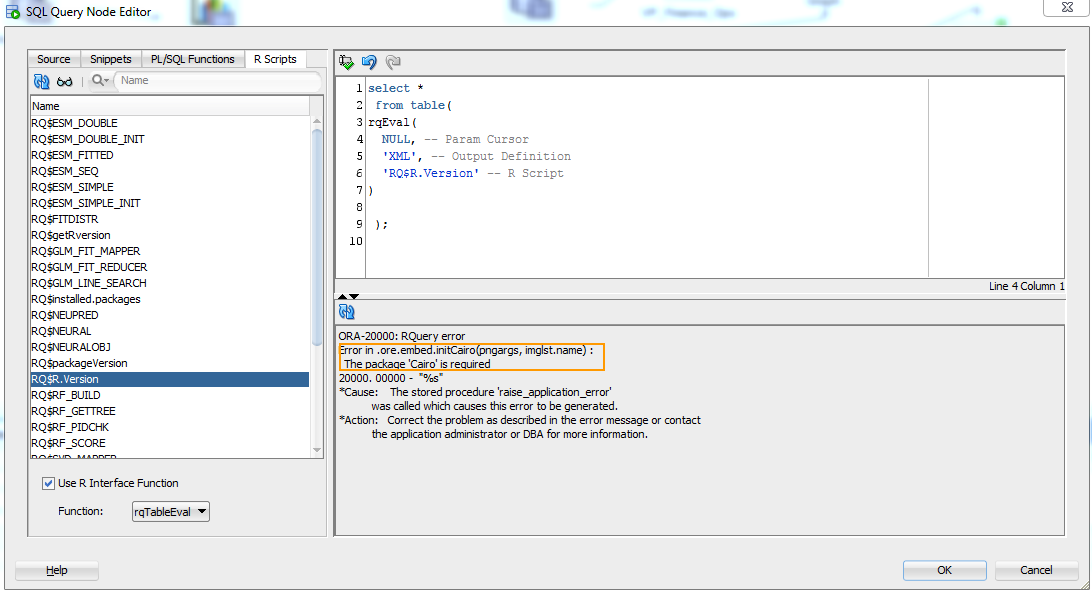
But as you can see, not so fact. Apparently we missed a step of installing supporting packaged. Although the admin guide says “On the server, the Oracle R Enterprise packages are installed automatically by the Oracle R Enterprise Server installation script”, it does not relate to supporting packages, one of which is Cairo.
To install the package from R we can use install.packages(“Cairo”) command:
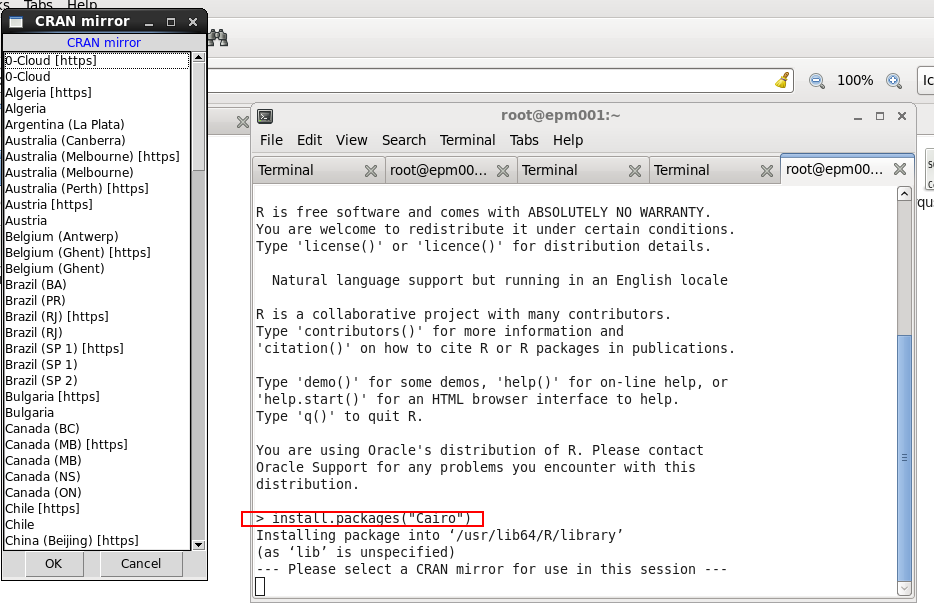
But it actually fails with “configure error: cannot find cairo.h”
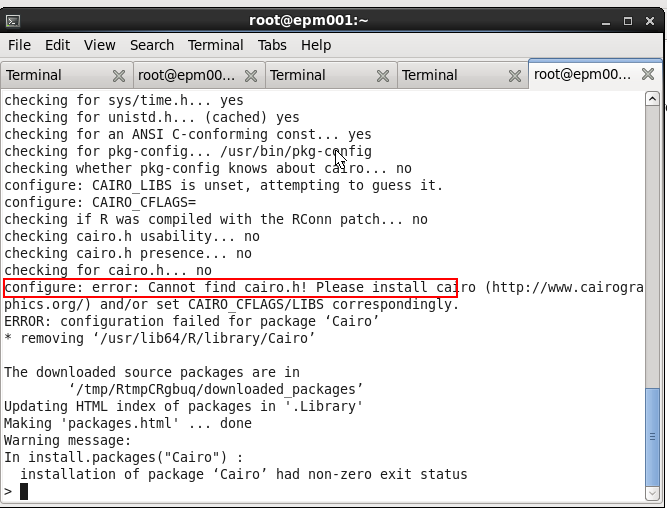
If we install another supporting package mentioned in the admin guide - “arules” - it works just fine, so the problem is with that particular Cairo package.
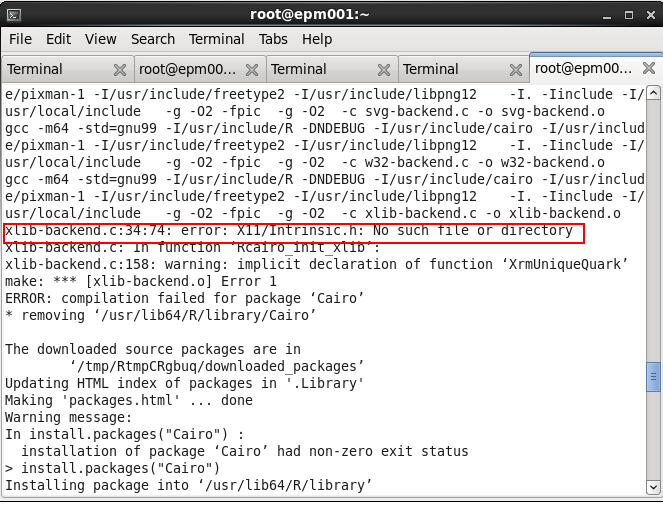
After a couple of burned hours and some research i found that cairo-devel.x86_64 needs to be installed as well.
yum install cairo-devel.x86_64
|
It moved us one step further, but we are not there yet. Now we get “xlib-backend.c:34:74: error: X11/Intrinsic.h: No such file or directory”
After installing the following packages finally Cairo package was installed successfully.
yum install libX11
yum install libX11-devel
yum install libXt
yum install libXt-devel
|
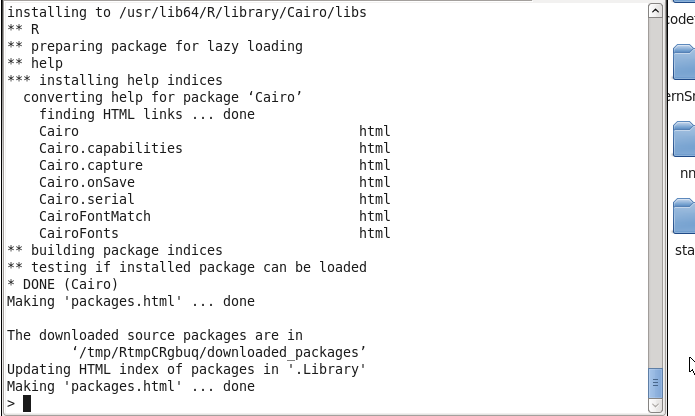
Lets validate our dataminer function now. This time we get:
Error in .ore.embed.initCairo(pngargs, imglst.name) :
The package 'png' is required
|
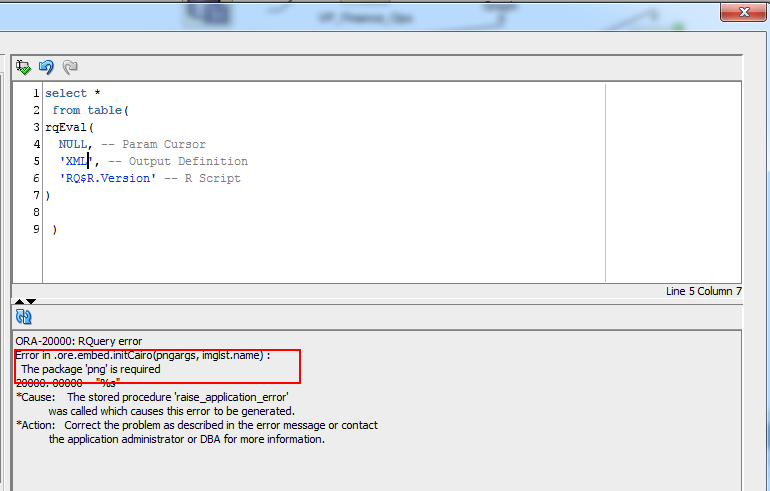
Finally, we install png package
install.packages(“png”)
And we pass the validation:
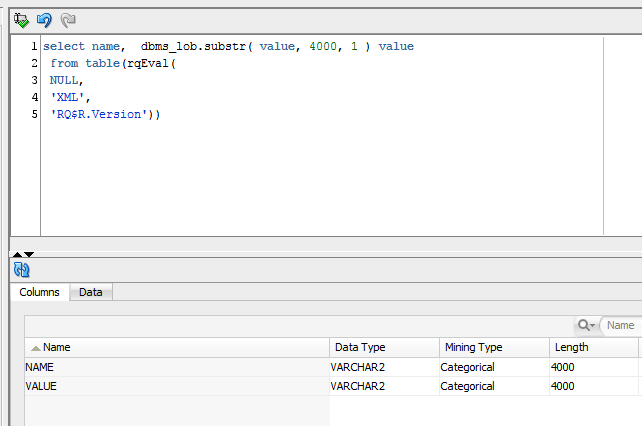
Let me reiterate: we don’t have to use data miner workflow or any of its nodes to use the prebuilt R script. Once R and its packages are installed we can run the same query from SQLPlus or SQl developer query, or use it anywhere else in our code:

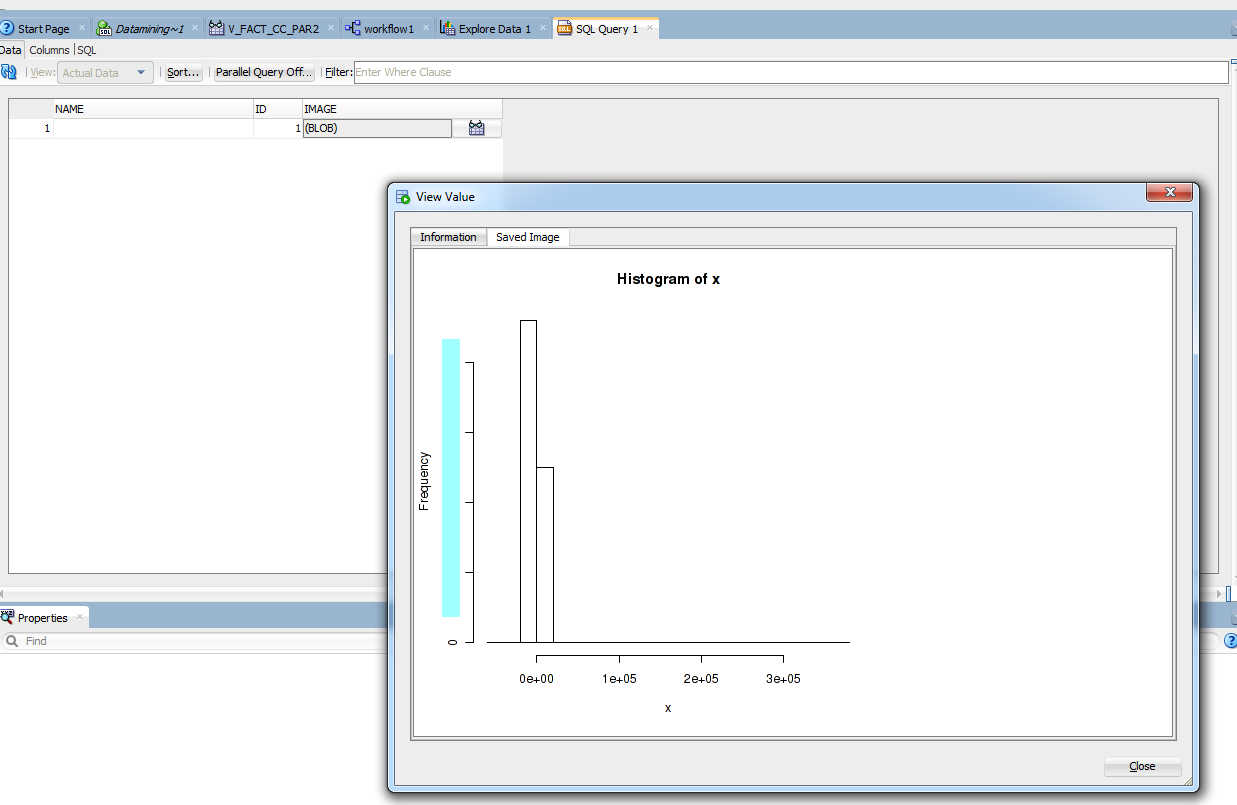
Below is an example of PNG output. The following query generates a graph which is stored in the database in CLOB field.
select *
from table(rqTableEval(cursor(select DATA from V_FACT_CC_PAR3), NULL,
'PNG',
'RQG$hist'))
|
At this point we are ready to proceed to really cool stuff - integrating Essbase with Data Miner and ORE.
No comments:
Post a Comment