
Overview
In the next several posts i’m going to show how to automate extracts from EPMA into relational database, integration with Essbase studio, and automate deployment of studio models. All with native Oracle tools like ODI, LCM with a bit of Jython used in ODI procedures.
Below is a high-level diagram of our end-to-end workflow.
- Administrator updates Shared Hierarchies
- Administrator creates shell application and updates application overrides in EPMA. There is no need to deploy those applications - they serve only as a container for local dimensions and overrides.
- When ODI job is triggered, it accepts the following parameters:
- Application name
- Plantype (optional - if EPMA planning shell contains multiple plantypes)
- List of dimensions (or All)
- ADS sections (Members|Hierarchies|PropertyArray)
- The job will push EPMA metadata and custom overrides into staging area.
- ODI automates LCM extract of metadata from EPMA into ADS files
- ADS files is processed
- Each file is loaded into corresponding tables.
- Tables structure is updated based in new metadata.
- EMPA application overrides are parsed
- Views are dynamically created for each application/dimension combination
- If Studio model is defined, ODI deploys the cube (optionally)
- If Studio schemas and models are not defined yet, administrator creates them in Essbase Studio.
There are a few legitimate questions you are probably asking right now.
- Q: Why would you want all this if Essbase Studio allows integration with EPMA?
- A1: EMPA -> Studio integration works with shared dimensions only. If you have to incorporate local dimensions, or properties overrides you may have at application level - default integration will not be sufficient.
- A2:You may want to have your metadata in relational database before it is consumed by Studio. For a variety of reasons:
- For example you may want to use that metadata in your queries of transactional sources for drill-through reports.
- Or you may want to allow consumption of that metadata by other systems.
- Or you may want to query that metadata to see the history of updates and have multiple historical snapshots of your hierarchies (you see where i’m getting, right?).
- You may want to combine EPMA metadata with metadata or data from other sources. With all due respect to Hyperion applications, they are a few others out there.
- A4: You may want to allow additional layer of overrides on top of your EPMA application overrides. One example is when you want to consume the same application metadata for planning and ASO applications (weird, right?).
- Q: Why wouldn’t you use DRM for that?
A: In a perfect world that’s what i would probably do. (Actually in a perfect world i would be doing something totally different. But that’s for another post).
LCM Extract Automation
In this post I’ll start with LCM extract of an application. It’s a package that can be use for many different purposes, and it is generic. You can use it for export, import, turning maintenance mode on Planning applications, whatever you usually do with LCM.
You just need to pass a LCM xml config file (tokenized) as a parameter, application name you want to use in config file, and timestamp to differentiate between exports.
Here, as well as in many other places i use tokenized templates. Meaning a template LCM definition file (in other places you can use MAXL files, SQL Loader files, or any text file) is parsed by the same ODI procedure that replaces tokens with parameter values. Please read more in this OTN article. It also has a code of the procedure.
In the context of EPMA extract LCM definition looks like this (EPMAExportConfig.xml):
<?xml version="1.0" encoding="UTF-8"?>
<Package name="web-migration" description="Migrating Product to File System">
<LOCALE>en_US</LOCALE>
<Connections>
<ConnectionInfo name="MyHSS-Connection1" type="HSS" description="Hyperion Shared Service connection" user="<UserToken>" password="<PassToken>"/>
<ConnectionInfo name="FileSystem-Connection1" type="FileSystem" description="File system connection" HSSConnection="MyHSS-Connection1" filePath="/<FlexOption2>"/>
<ConnectionInfo name="AppConnection2" type="Application" product="BPMA" project="Foundation" application="EPM Architect" HSSConnection="MyHSS-Connection1" description="Source Application"/>
</Connections>
<Tasks>
<Task seqID="-1">
<Source connection="AppConnection2">
<Options/>
<Artifact recursive="true" parentPath="/Application Metadata/Planning Applications/<FlexOption1>/Local Dimensions" pattern="*"/>
<Artifact recursive="true" parentPath="/Shared Library Dimensions" pattern="*"/>
<Artifact recursive="true" parentPath="/Application Metadata/Planning Applications/<FlexOption1>/Planning Settings" pattern="*"/>
</Source>
<Target connection="FileSystem-Connection1">
<Options/>
</Target>
</Task>
</Tasks>
</Package>
|
As i said, this file is essentially a tokenized template. Its tokens (<UserToken>,<PassToken>,<FlexOption1>,<FlexOption2>) are replaced with ODI parameters and username/password queried from ODI repository.
Tokenized template allows
- Running this scenario on any application: parentPath="/Application Metadata/Planning Applications/<FlexOption1>/Local Dimensions"
- Exporting metadata into directory with dynamic name with timestamp(in our case #APPNAME#TIMESTAMP_SEC).
There are 3 sections we are interested to export:
- /Application Metadata/Planning Applications/<FlexOption1>/Local Dimensions
- /Application Metadata/Planning Applications/<FlexOption1>/Planning Settings
- /Shared Library Dimensions
The first 2 sections will export local dimensions and application overrides, whereas the third section will export shared dimensions.
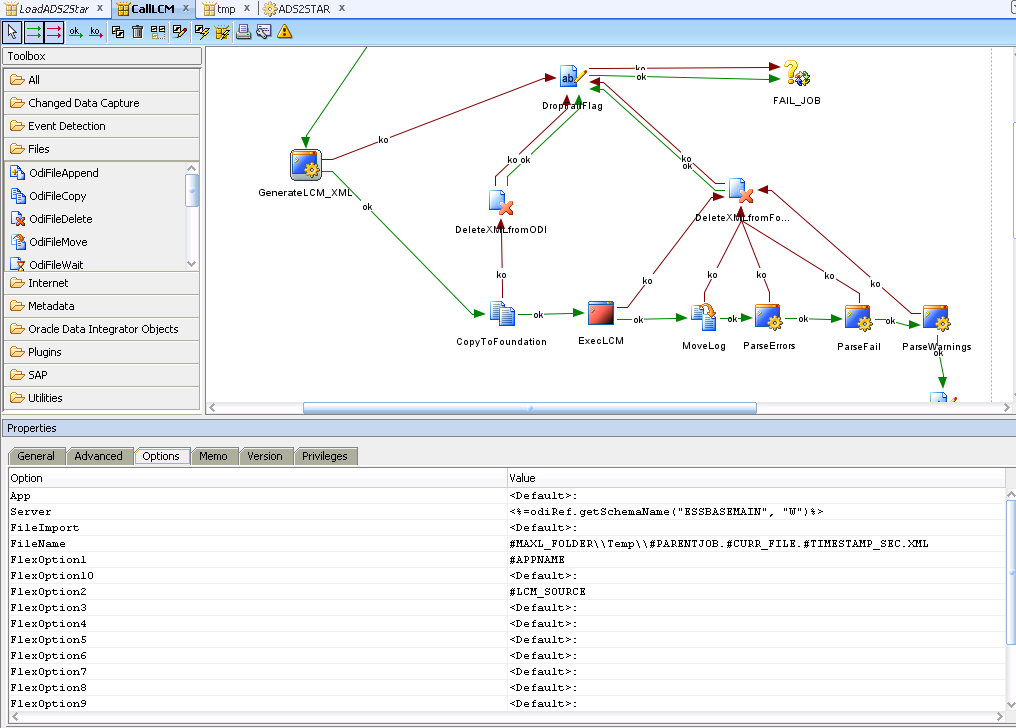
- Within CALLLCM scenario the first step is to generate actual XML definition file based on tokenized template (EPMAExportConfig.xml). GenerateLCM_XML procedure replaces tokens and creates and creates an XML file. Again it’s just the instance of the same procedure that replaces tokens.
- The generated LCM definition file is copied to foundation server
- PSEXEC command triggers callLCM.bat on foundation server which runs LCM job
- Then log is moved from foundation into ODI and error parsing happens.
Loading ADS Files Dynamically Into Staging Area
Once we extracted EPMA application and shared dimensions with LCM, we ended up with a bunch of ADS files, and one XML file for overrides. (EPMA, how about some consistency in file formats? Well, this is not the last inconsistency we are going to see...).
Preparing a List
We may not necessarily want to load/reload all dimensions and all sections of a particular application into staging area. Also, you probably don’t use all of your shared dimensions in a single application. Hence, we need to pass 2 lists as parameters: lists of dimensions, and a list of ADS sections.
- For dimensions it’ll look something like: Account|TimePeriod|Currency|BusinessUnit|Entity|CostCenter|Version…
- For sections: Members|Hierarchies|PropertyArray
At this point ODI will need to go the folder with ADS files extracted by LCM, and load only those dimension-section combinations we specified in the parameters. It’s quite easy to do for dimensions, since the files are called the same as dimensions (\LoadADS2Star\Data\MyApp20160217214515\resource\Shared Library Dimensions\Account)
As you can see the folder name contains the timestamp so by running this job you also automatically generated EPMA backup. How are you actually generating the list of files that need to be loaded? That's done with the help of a little Jython script. You can notice that instead o
import os
import fnmatch
import re
import glob
# -----------------------------------------------------------------------------
# Get parameters from scenario.
# -----------------------------------------------------------------------------
path = '<%=odiRef.getOption("ReadFolder")%>'
current_timestamp='<%=odiRef.getOption("TIMESTAMP_SEC")%>'
Dim_List_option='<%=odiRef.getOption("Dim_List")%>'
ListFileName_option='<%=odiRef.getOption("ListFileName")%>'
file_list=''
# -----------------------------------------------------------------------------
# Path value is #LOG_FOLDER\\Data\\\#APPNAME#TIMESTAMP_SEC
# For example:
# Hyperion\logs\essbase\odi\Maxl\LoadADS2Star\Data\MyApp20151221222016
# The name of the folder with metadata contains application name and
# a timestamp. In the next loop we walk through all the files in the metadata
# folder, including subdirectories, and prepare the list of files to be parsed.
# -----------------------------------------------------------------------------
for root, dirnames, filenames in os.walk(path):
for filename in filenames:
# -----------------------------------------------------------------------------
# We don't want to include XML files or Overrides file in our list.
# We only need to get ADS files. Hence the next condition.
# -----------------------------------------------------------------------------
if filename.find('.xml')==-1 and filename.find('Filters and Overrides')==-1:
# -----------------------------------------------------------------------------
# If we push all dimensions simply add the current file to the file_list.
# Otherwise loop through the list of dimensions passed into ODI job
# (Dim_List_option), and if current file matches one of the dimensions in the
# list, add it to file_list. Example of the output:
# \\resource\\Shared Library Dimensions\\EmpType|\\resource\\Shared..\\Entity
# File names are separated with pipe (|).
# Example of the output file is ADSList.20151221061559.txt.
# -----------------------------------------------------------------------------
if(Dim_List_option.upper()=='ALL'):
file_list=file_list+os.path.join(root, filename).replace(path,'').\
replace('\\','\\\\')+'|'
else:
for dim in Dim_List_option.split('|'):
if filename.upper().find(dim.upper())>=0:
file_list=file_list+os.path.join(root, filename).replace(path,'').\
replace('\\','\\\\')+'|'
output_write=open(ListFileName_option,'w')
output_write.write(file_list)
output_write.close()
|
In the next post i’ll share SQLLoader template and the code that actual control file and data files from ADS files. Stay tuned...
No comments:
Post a Comment