
At this point we know what files we need to load (see previous post). Now let's use ODI to load them into staging area.
But we may have some 20 dimensions (including attribute dimensions) that need to be loaded, and three sections in each ADS file. So in total 60 dimension/section/combinations. Plus we probably have multiple applications to load. Each of those combinations will have a different structure in terms of columns that need to be loaded. Clearly different sections of the ADS file have different properties (columns), but also the same section of different dimensions may have different columns.
Attribute dimensions is one of the reasons for the difference. Different base dimensions are associated with different sets of attribute dimensions. Since each attribute dimension has a separate column in ADS file, the number and the order of columns in ADS file will be different. So we have two options:
- Create a separate model for each application/dimension/section combination in ODI. This would be utterly insane waste of time. (Well, if you are a consulting company, this will be a very profitable opportunity). Also this kind of solution would be completely unscalable. You would need to change your process every time you add a new attribute dimension to your application
- The better option is to use dynamically generated SQL Loader files. By now you probably know what method I will use to create them. Yes, tokenized control templates.
To summarize, this is the list of requirements for ADS loading process:
- We need to create target columns dynamically before attempting to load data (again, since the structure of ADS files is different for dimension/section/application combinations).
- In order to enable comparison between two metadata loads we need to add a single timestamp for all records loaded during one instance of the job.
- ADS files do not contain values for member order, hence we need to generate member order value based on position in ADS files.
- Dimensions may exist in both local library and in shared library. Hence we need to load Local/Shared indicator (based on the location of the source file on the file system).
- Target table will be determined based on the section we are loading. E.g. possible target tables are T_EPMA_MEMBERS, T_EPMA_HIERARCHIES, T_EPMA_PROPERTYARRAY.
Below is the template of SQL Loader control file.
OPTIONS (
SKIP=1,
ERRORS=0,
DIRECT=TRUE
)
LOAD DATA
INFILE "<SourceToken>.txt"
BADFILE "<SourceToken>.bad"
DISCARDFILE "<SourceToken>.dsc"
DISCARDMAX 0
APPEND
INTO TABLE T_EPMA_<SectionToken>
fields terminated by "|"
TRAILING NULLCOLS
(
<FIELDSTOKEN>,
LOADSTAMP "<FlexOption4>",
LOADTIME "CURRENT_TIMESTAMP(1)",
MEMBERORDER SEQUENCE(1,1),
APPLICATION "'<AppToken>'",
DIMENSION "'<DimToken>'",
DIMLOCAL "'<DimLocalToken>'"
)
|
A few words about the tokens:
- The target table is defined dynamically with <SectionToken>. Based on the currently loaded section the target table will be T_EPMA_MEMBERS, T_EPMA_HIERARCHIES, T_EPMA_PROPERTYARRAY.
- <FIELDSTOKEN> defines the fields that exist in the source ADS file. Those will be different for application/dimension/section combination.
- <FlexOption4> is a timestamp passed from ODI. The timestamp will be identical for all records loaded with this control file. This is the way to identify multiple snapshots of metadata.
- <AppToken> and <DimToken> are self-explanatory.
- <DimLocalToken> is an indicator whether dimension is local or shared.
Let's see how dynamically generated control file looks (I had to obscure path name and attribute dimension names) for the case of account-members combination.
OPTIONS (
SKIP=1,
ERRORS=0,
DIRECT=TRUE
)
LOAD DATA
INFILE "...\EPMA_CostCenter_Hierarchies.20160217214515.20160217215207.txt"
BADFILE "...\EPMA_CostCenter_Hierarchies.20160217214515.20160217215207.bad"
DISCARDFILE "...\EPMA_CostCenter_Hierarchies.20160217214515.20160217215207.dsc"
DISCARDMAX 0
APPEND
INTO TABLE T_EPMA_HIERARCHIES
fields terminated by "|"
TRAILING NULLCOLS
(
PARENT char(4000),CHILD char(4000),ISPRIMARY char(4000),AGGREGATIONWEIGHT char(4000),ASOMEMBERDATASTORAGE char(4000),BSOMEMBERDATASTORAGE char(4000),CAPEXAGGREGATION char(4000),CONSOLIDATION char(4000),DATASTORAGE char(4000),FULLYQUALIFIEDSHAREDMEMBER char(4000),MEMBERVALIDFORCAPEX char(4000),MEMBERVALIDFORPLAN1 char(4000),MEMBERVALIDFORPLAN2 char(4000),MEMBERVALIDFORPLAN3 char(4000),MEMBERVALIDFORWORKFORCE char(4000),PLAN1AGGREGATION char(4000),PLAN2AGGREGATION char(4000),PLAN3AGGREGATION char(4000),WORKFORCEAGGREGATION char(4000),ASOMEMBERFORMULA char(4000),BSOMEMBERFORMULA char(4000),Attr_1 char(4000),Attr_2 char(4000),Attr_3 char(4000),Attr_4 char(4000),Attr_5 char(4000),COMMENT char(4000),Attr_6 char(4000),DATATYPE char(4000),DESCRIPTION char(4000),FORMATSTRING char(4000),HIERARCHYTYPE char(4000),ISCALCULATED char(4000),MEMBERSOLVEORDER char(4000),Attr_7 char(4000),PRIMARYLEVELWEIGHTING char(4000),SECURITYCLASS char(4000),SMARTLIST char(4000),SUBMISSIONGROUP char(4000),SWITCHSIGNFORFLOW char(4000),SWITCHTYPEFORFLOW char(4000),TWOPASSCALC char(4000),USERDEFINED1 char(4000),USERDEFINED2 char(4000),USERDEFINED3
,
LOADSTAMP "20160217214515",
LOADTIME "CURRENT_TIMESTAMP(1)",
MEMBERORDER SEQUENCE(1,1),
APPLICATION "'MyApp'",
DIMENSION "'CostCenter'",
DIMLOCAL "'NO'"
)
|
You can see that this template will work for any application, dimension or ADS section. And you don’t have to create separate models, interfaces and map sources to targets for every combination
Created By Jython
Below are relevant pieces of Jython code used to create dynamic SQL Loader control files, and update tables structure dynamically.
The first step is to import libraries, and get parameters from ODI procedure options.
import os
import fnmatch
import re
import glob
import shutil
# -----------------------------------------------------------------------------
# Get parameters from scenario, initialize variables.
# -----------------------------------------------------------------------------
ReadFile='<%=odiRef.getOption("ReadFile")%>'
current_section='<%=odiRef.getOption("Section")%>'
SQLLDRControlOption='<%=odiRef.getOption("SQLLDRControl")%>'
SQLLDRTemplate_filename='<%=odiRef.getOption("SQLLDRTemplate")%>'
FlexOption2Option='<%=odiRef.getOption("FlexOption2")%>'
plantype='<%=odiRef.getOption("FlexOption9")%>'
plantypeinname='<%=odiRef.getOption("FlexOption10")%>'
App_option='<%=odiRef.getOption("App")%>'
create_view_option='<%=odiRef.getOption("FlexOption7")%>'
regex = fnmatch.translate( '!'+current_section+'='+'*')
current_section_re = re.compile(regex)
control_file=''
section_start=0
ADSstr=''
ADSfields=''
SQLLDRTemplateStr=''
|
DIMLOCAL column is one of those fields that help us to determine whether dimension needs to be loaded from shared library or local. If the current file is loaded from the file containing 'Local Dimensions' in its path DIMLOCAL will get the value YES (I guess 1 or True would be more efficient).
# -----------------------------------------------------------------------------
# ReadFile is the source ADS file to be parsed.
# If the file contains "Local Dimensions" in its path (meaning we are parsing
# local dimension obviously), local_token will get value "YES" and will be
# loaded into DIMLOCAL column.
# -----------------------------------------------------------------------------
if os.path.exists(ReadFile):
ofile=open(ReadFile, 'r')
if ReadFile.find('Local Dimensions')>0:
local_token='YES'
else:
local_token='NO'
|
Here’s another peculiarity of ADS file properties and the formula value. As the code comment mentions, LCM replaces new line in formulae with underscore (_) and new line. We cannot allow that, since every record loaded into a table with SQL Loader is assumed to be a separate line. I’m sure there are a few alternatives how we could deal with this situation, but that’s what we currently do. So we create a new file with _prep in the end of the file name. All '_\n' are removed.
# -----------------------------------------------------------------------------
# LCM replaces new line in formulae with underscore (_) and new line.
# We need to get rid of that, so that each line in ADS file correspond to
# single record/member. so we create a new file with _prep in the end
# of the file name. All '_\n' are removed.
# -----------------------------------------------------------------------------
for line in ofile:
ADSstr=ADSstr+line.replace('_\n','')
out_file_name=ReadFile+'_prep'
out_file=open(out_file_name,'w')
out_file.write(ADSstr)
out_file.close()
ADSstr=''
ofile=open(ReadFile+'_prep', 'r')
|
The next section is parsing the ADS file and getting the relevant section to be loaded. We also derive dimension name from the file name, and create control filename.
# -----------------------------------------------------------------------------
# Read the relevant section of the file into ADSstr variable.
# Get the dimension name from the file name.
# Write the content into a file that will be the source file in SQLLDR.
# It will replace INFILE "<SourceToken>.txt" in SQLLDR template.
# Read the first row of the section into ADSfields variable. It will be used
# in SQLLDR file to populate the list of target columns.
# -----------------------------------------------------------------------------
for line in ofile:
header_line=0
if current_section_re.match(line):
section_start=1
ADSfields=ofile.next()
header_line=1
dimension_name=line.replace(current_section,'').replace('\n','').replace('!','').replace('=','')
control_file=SQLLDRControlOption.replace('template','%s_%s' % (dimension_name,current_section))
if len(line.strip())==0 and section_start==1:
break
if section_start==1 and header_line==0:
ADSstr=ADSstr+line
ADSstr=ADSfields+ADSstr
out_file_name=control_file.replace('ctl','txt')
out_file=open(out_file_name,'w')
out_file.write(ADSstr)
out_file.close()
|
Finally, we read SQL Loader control template, replace all the tokens, and write it to disk for subsequent execution.
# -----------------------------------------------------------------------------
# Read SQLLDR template. Replace list of fields with ADSfields from source file.
# Replace other tokens. Write control file and append timestamp to the name.
# -----------------------------------------------------------------------------
if os.path.exists(SQLLDRTemplate_filename):
SQLLDRTemplate_file=open(SQLLDRTemplate_filename, 'r')
for line in SQLLDRTemplate_file:
SQLLDRTemplateStr=SQLLDRTemplateStr+line
ADSfields=ADSfields.replace('\'','').upper()
ADSfields=ADSfields.replace(',',' filler char(4000),')
SQLLDRTemplateStr=SQLLDRTemplateStr.replace('<AppToken>',App_option)
SQLLDRTemplateStr=SQLLDRTemplateStr.replace('<DBToken>','<%=odiRef.getOption("DB")%>')
SQLLDRTemplateStr=SQLLDRTemplateStr.replace('<DimToken>',dimension_name)
SQLLDRTemplateStr=SQLLDRTemplateStr.replace('<DimLocalToken>',local_token)
SQLLDRTemplateStr=SQLLDRTemplateStr.replace('<FIELDSTOKEN>',ADSfields.replace('|',' char(4000),'))
SQLLDRTemplateStr=SQLLDRTemplateStr.replace('<SourceToken>',out_file_name.replace('.txt',''))
SQLLDRTemplateStr=SQLLDRTemplateStr.replace('<SectionToken>',current_section.upper())
SQLLDRTemplateStr=SQLLDRTemplateStr.replace('<FlexOption3>','<%=odiRef.getOption("FlexOption3")%>')
SQLLDRTemplateStr=SQLLDRTemplateStr.replace('<FlexOption4>','<%=odiRef.getOption("FlexOption4")%>')
SQLLDRTemplateStr=SQLLDRTemplateStr.replace('<FlexOption5>','<%=odiRef.getOption("FlexOption5")%>')
SQLLDRTemplateStr=SQLLDRTemplateStr.replace('<FlexOption8>','<%=odiRef.getOption("FlexOption8")%>')
SQLLDRTemplateStr=SQLLDRTemplateStr.replace('<FlexOption9>','<%=odiRef.getOption("FlexOption9")%>')
SQLLDRTemplateStr=SQLLDRTemplateStr.replace('<FlexOption10>','<%=odiRef.getOption("FlexOption10")%>')
out_file=open(control_file,'w')
out_file.write(SQLLDRTemplateStr)
out_file.close()
|
Now suppose you are trying to load data with SQL Loader file into one of those 3 tables (T_EPMA_MEMBERS, T_EPMA_HIERARCHIES, T_EPMA_PROPERTYARRAY). As we said, the list of fields for current intersection of application/dimension/section could be very different from the fields we loaded previously. For example, we could have added a new attribute dimension “Product_Type” for one of the base dimensions. That means the Hierarchy section of the ADS file will have a new column. That column doesn’t exist yet in T_EPMA_HIERARCHIES, since “Product_Type” never was loaded before. All that meant we need to update the table before we attempt to load the ADS file. And that is the purpose of the following section:
# -----------------------------------------------------------------------------
# We also need to add columns to a table in case they don't exist. This
# situation can happen when a new attribute was added to a dimension, so the old
# table structure doesn't work for current application.
# -----------------------------------------------------------------------------
alter_table_str=''
for field in ADSfields.split('|'):
alter_table_str='%s ALTER TABLE T_EPMA_%s ADD "%s" varchar2(4000);\n' % \
(alter_table_str,\
'<%=odiRef.getOption("Section")%>'.upper(),\
field.replace('\n','').replace('\r',''))
spool_file=control_file.replace('.ctl','_DDL.log')
alter_table_str='spool %s\n%s\ncommit;\nspool off\nquit;\n' % (spool_file,alter_table_str)
alter_table_file=open(FlexOption2Option,'w')
alter_table_file.write(alter_table_str)
alter_table_file.close()
|
How is that file going to be executed? In the same ODI procedure we’ll have a separate update_table step:
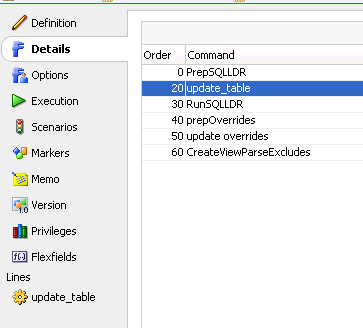
It will run sqlplus statement as ODIOScommand. Again, there are other ways to do the same, if you feel strongly about it add a comment and i will add it to the post.
# -----------------------------------------------------------------------------
OdiOSCommand
sqlplus <%=odiRef.getInfo("SRC_USER_NAME")%>/<%=odiRef.getInfo("SRC_PASS")%>@<%=odiRef.getInfo("SRC_DSERV_NAME")%> @"<%=odiRef.getOption("FlexOption2")%>"
|
In order for the command to work and to get username/password correctly from physical topology we need to specify source technology and schema.
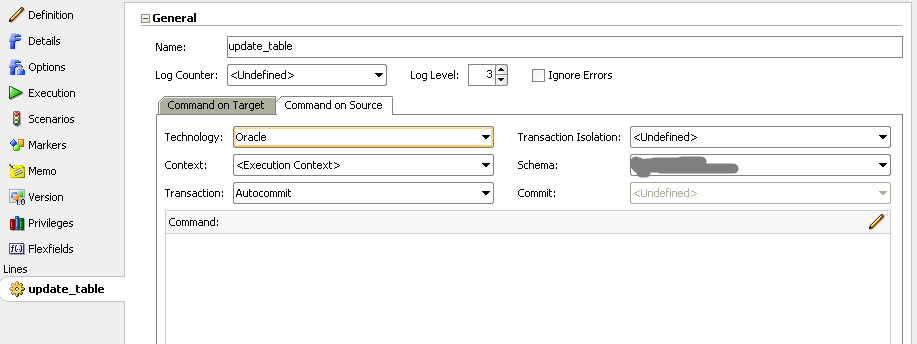
Load. Finally.
Once the ODI procedure updated the structure of the tables, it will load ADS files dynamically created SQLLoader control files.
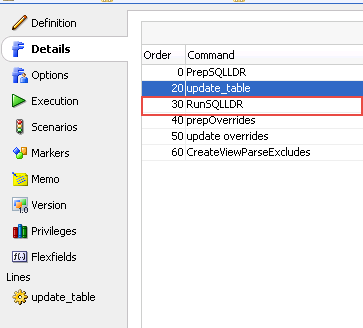
OdiOSCommand
sqlldr <%=odiRef.getInfo("SRC_USER_NAME")%>/<%=odiRef.getInfo("SRC_PASS")%>@<%=odiRef.getInfo("SRC_DSERV_NAME")%> control=#LOG_FOLDER\EPMA_run.#TIMESTAMP_SEC.#TIMESTAMP_SEC2.ctl LOG=#LOG_FOLDER\EPMA_run.#TIMESTAMP_SEC.#TIMESTAMP_SEC2.log
|
The command is similar to previous one (calling sqlplus), this one calls SQLLDR. The source definition should be the same as for sqlplus.
You can see that the next step in procedure is prepOverrides. It will take care of the XML file that has all application level overrides. In the next post we’ll review that step. Stay tuned!
No comments:
Post a Comment